Rearranging Raspberry Pi

Replacing the production DB under a running system.
Two years ago we migrated Raspberry Pi from a single big server to a series of virtual machines (VMs) on an even bigger server. As time has gone on this architecture served us well; we’ve managed the Pi Zero launch and the busier Raspberry Pi 3 launch and even briefly ran the website on Raspberry Pis as a test.
However, we had a number of issues with the setup that we were looking to address:
- We were out of space at the back end and needed more capacity;
- We wanted more redundancy: the setup was dependent on a single dedicated VM host in a single data centre; and
- There’s an apparent hardware fault on the current VM host that causes it to very occasionally spontaneously reboot (or in one case, switch itself off altogether)
It was time for a bit of an upgrade.
Scalable WordPress
The biggest part of the Raspberry Pi configuration is the main WordPress site that serves the front page for www.raspberrypi.org. This consisted of three VMs: two web servers and one database server. WordPress doesn’t provide any built-in functionality for scaling to multiple servers and although the vast majority of pages are driven entirely by the database, some operations, such as installing plugins or uploading media, result in the creation of local files that need to be available to all web servers.
In order to support WordPress in a multi-server configuration, we arrange the two web servers as a primary and a secondary. The primary delivers half of the public requests and also the administration and content creation side. The relevant parts of the local filesystem are then regularly rsynced to the secondary server, which serves public requests and can maintain the support the full public usage of the site if necessary.
The website is fronted by our “CDN”. This is a cluster of Mac Mini servers that we use to offload much of the static content traffic, and to load balance across the two web servers.
Step 1 : Figure out what you’re trying to do and write a plan.
More capacity meant a new VM host, and more redundancy meant that it went in a different data centre (Sovereign House, or “SOV”) to the existing VM host (Harbour Exchange, or “HEX”).
Diagnosing the fault on the current VM host is tricky, firstly because it only occurs once or twice a year, and secondly because it was hosting quite a busy live website. So our plan for this was to migrate all VMs onto entirely new hardware in HEX so that we can prod the old box at our leisure. This also gave us a handy opportunity to do something we’ve been wanting to do for a while, which is an OS upgrade on the VM host itself.
To add redundancy to the main site, we can split the two web server VMs across the two sites, but this doesn’t help unless we also replicate the database at the new site. So overall, we wanted to move one web server VM to SOV, and add a database VM, and in HEX we wanted to move the database VM and remaining web server VM to the new hardware. This all needed to be achieved with minimal downtime; as a highly public site we’d rather not have two hours of downtime if we can avoid it.
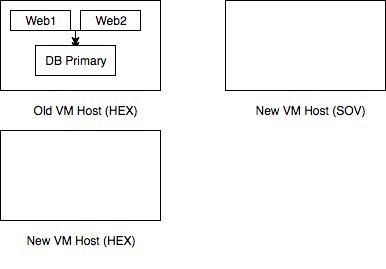
Step 2 : Move the database
We brought up a second database VM at the second site (SOV). We set this up as a MySQL replica of the primary database VM, this requires only the briefest of interruptions to service to configure. We then simulated a failure of the primary database server and moved all database services to the alternative site – so the database is now in SOV. Again, this has only a very brief interruption to service (<5s).

We then moved the old database VM to the new VM host in the original site (HEX) and reconfigured it as a MySQL replica. We now have a primary/secondary setup for MySQL on the new VM hosts, the secondary in a different location (HEX) to the primary (SOV), and the HEX server is not longer on the faulty hardware.

It’s worth noting that in normal operation, both web servers use the same database server for all queries. In similar arrangements, it’s quite common to have one or more web server use the slave database server for read queries, and to only send write queries to the master, thereby reducing the load on the primary database server. Unfortunately, standard WordPress doesn’t support this, but there are plugins that do which we may look at in the future.
Step 3 : Move the web servers
We shut down the secondary web server (HEX), moved it to the replacement VM host in the same data centre and brought it back up. The CDN automatically redirected all web traffic to the primary web server until the secondary came backup. Once this was complete we took the primary web server offline disabling all administration functions for the main website. Fortunately we’d told everyone in the Raspberry Pi office to drink coffee while we did this so nobody complained. Again the CDN moved all production traffic to the secondary web server, we then moved the primary VM to our alternative data centre (SOV) to sit next to the primary database server (SOV).

Step 4 : Tell the CDN
Unlike many providers, we have independent routing at each of our sites. This gives us much greater resilience to network problems, but means that moving a VM between sites necessitates a change in IP address. We informed our cluster of Mac Minis in the CDN that the primary web server had moved, and the administration site sprung back into life and the traffic split evenly across the two sites.
Step 5 : Drink coffee
Over the course of about three hours, we’d migrated a high volume production website from a non-redundant, single site configuration to a geographically redundant configuration, moved the primary database and primary web server to a different location and provided a capacity upgrade. This was all done in the middle of the day with no user-facing downtime, and only a modest maintenance window for the administration portal.
With that done, we can start work on the next stage of the plan: migrating the remainder of the VMs away from the old VM host in HEX.