Website update
Rather than pictures of text, we prefer actual text.
We’ve recently updated the look and feel of our homepage. All the work has been done in-house by our own staff, and we’re hopeful that other organisations might steal some of our unusual ideas:
- No pop-ups; any feature requiring a cookie banner will not be permitted, and you definitely won’t be pestered to join a mailing list.
- The website should clearly state what services we offer and how much they cost.
- The website should be fully accessible.
- No third party dependencies – everything is served from a mythic-beasts.com domain on servers we own and operate.
- Minimal number of HTTP requests and small pages so our front page is faster than the home page of high performance content delivery networks.*
- No existing feature should stop working as a result of the redesign.
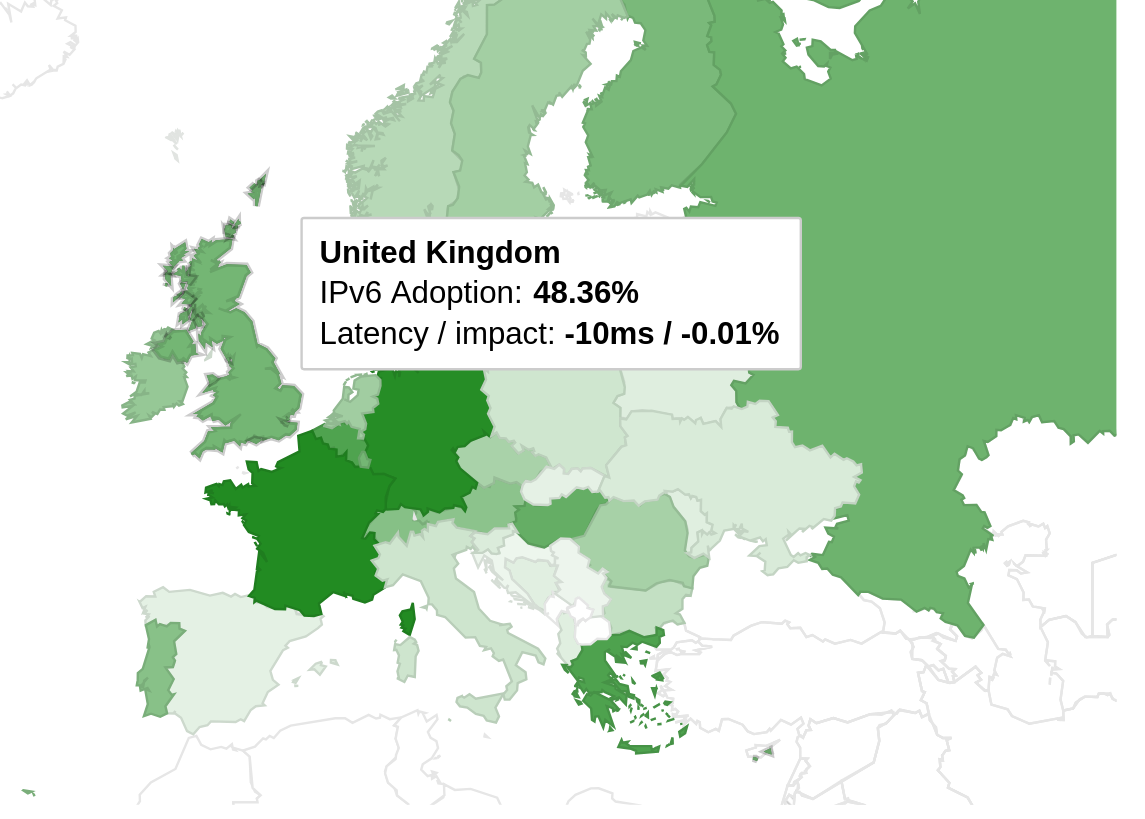
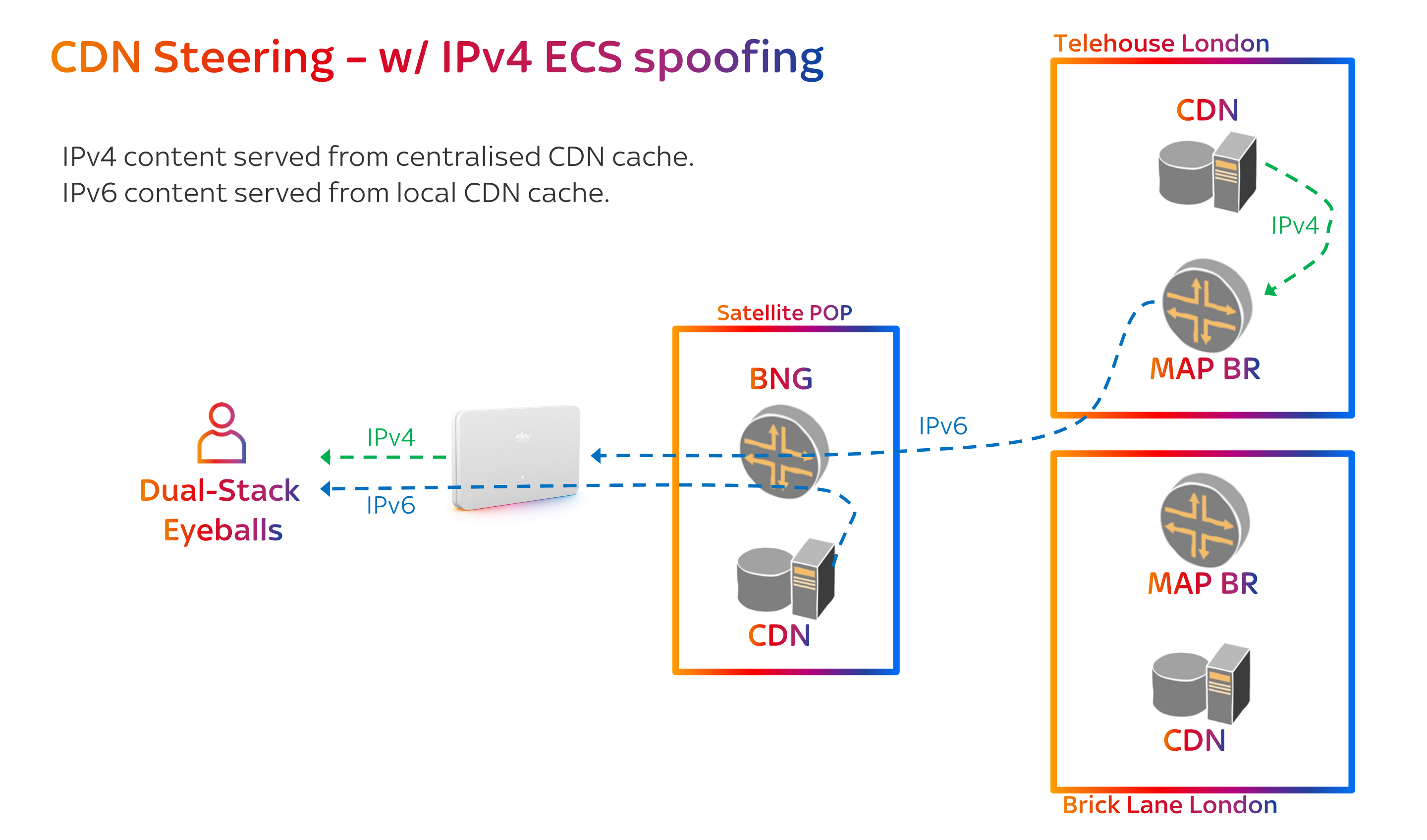
- Works perfectly for an IPv6-only user.
In updating our homepage, we’ve tried to better describe what it is that makes us different and in order to backup our claims of “fair, no-nonsense pricing” we’ve now documented our pricing policy in unnecessary detail.
We are always adding features to our website and control panel, and over the last year we’ve had a particular focus on improving accessibility. We now have an internal instance of Pa11y which automatically checks our pages for accessibility issues. Pa11y caught an accessibility regression in our rollout which we’ve now resolved. If you do encounter accessibility issues on our site, please do report them.
We’re also in the process of updating our website to consistently show prices inclusive of UK VAT, and have now done so on our homepage. For historical reasons, we’re not consistent on this, although we do always state which one it is. VAT treatment is always tricky, as many of our customers are not in the UK and thus may pay a different rate of VAT, or no VAT at all, and we also have many VAT-registered customers who prefer ex-VAT prices. Showing VAT-inclusive prices can make us look more expensive compared to our competitors – always check that you’re comparing like with like.
* We measured our homepage at about 300ms, compared to 2-5s for popular content delivery network homepages we compared with.