IPv4/IPv6 transit in HE Fremont 2
Back in 2018, we acquired BHost, a virtual hosting provider with a presence in the UK, the Netherlands and the US. Since the acquisition, we’ve been working steadily to upgrade the US site from a single transit provider with incomplete IPv6 networking and a mixture of container-based and full virtualisation to what we have now:
- Dual redundant routers
- Two upstream network providers (HE.net, CenturyLink)
- A presence on two internet Exchanges (FCIX/SFMIX)
- Full IPv6 routing
- All customers on our own KVM-based virtualisation platform
With these improvements to our network, we’re now able to offer IPv4 and IPv6 transit connectivity to other customers in Hurricane Electric’s Fremont 2 data centre. We believe that standard services should have a standard price list, so here’s ours:
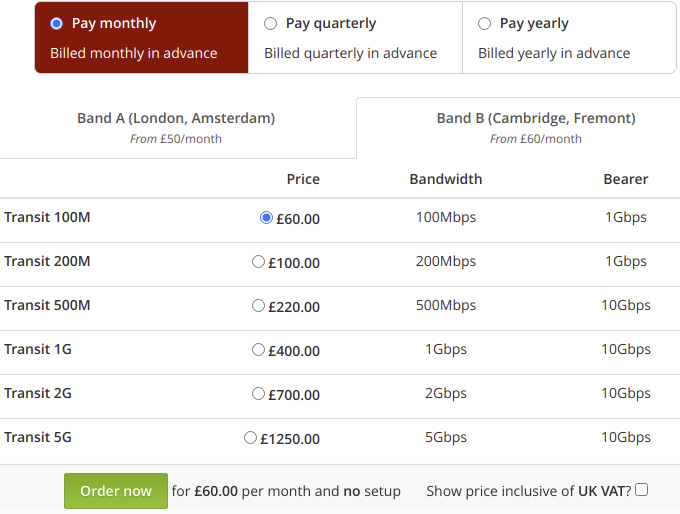
Prices start at £60/month on a one month rolling contract, with discounts for longer commits. You can order online by hitting the big green button, we’ll send you a cross-connect location within one working day, and we’ll have your session up within one working day of the cross connect being completed. If we don’t hit this timescale, your first month is free.
We believe that ordering something as simple as IP transit should be this straightforward, but it seems that it’s not the norm. Here’s what it took for us to get our second 10G transit link in place:
- 24th April – Contact sales representative recommended by another ISP.
- 1st May – Contact different sales representative recommended by UKNOF as one of their sponsors.
- 7th May – 1 hour video conference to discuss our requirements (a 10Gbps link).
- 4th June – Chase for a formal quote.
- 10th June – Provide additional details required for a formal quote.
- 10th June – Receive quote.
- 1st July – Clarify further details on quote, including commit.
- 2nd July – Approve quote, place order by email.
- 6th July – Answer clarifications, push for contract.
- 7th July – Quote cancelled. Provider realises that Fremont is in the US and they have sent EU pricing. Receive and accept higher revised quote.
- 10th July – Receive contract.
- 14th July – Return signed contract. Ask for cross connect location.
- 15th July – Reconfirm the delivery details from the signed contract.
- 16th July – Send network plan details for setting up the network.
- 27th July – Send IP space justification form. They remind us to provision a cross connect, we ask for details again.
- 6th August – Chase for cross connect location.
- 7th August – Delivery manager allocated who will process our order.
- 11th August – Ask for a cross connect location.
- 20th August – Ask for a cross connect location.
- 21st August – Circuit is declared complete within the 35 day working setup period. Billing for the circuit starts.
- 26th August – Receive a Letter Of Authorisation allowing us to arrange the cross connect. We immediately place order for cross connect.
- 26th August – Data centre is unable to fulfil cross connect order because the cross connect location is already in use.
- 28th August – Provide contact at data centre for our new provider to work out why this port is already in use.
- 1st September – Receive holding mail confirming they’re working on sorting our cross connect issue.
- 2nd September – Receive invoice for August + September. Refuse to pay it.
- 3rd September – Cross connect location resolved, circuit plugged in, service starts functioning.
Shortly after this we put our order form live and improved our implementation, we received our first order on the 9th September and provisioned a few days later. Our third transit customer is up and live, order form to fully working was just under twelve hours; comfortably within our promise of two working days.








